
百度AI搜索
百度AI搜索是基于大模型的智能搜索引擎,它整合了百度搜索、文库、健康、教育等核心内容生态,用户的回答会更精准和更多内容。
SkillOpt不仅在于技术细节,更在于它定义了一种新的 Agent 基础设施范式:技能不再是静态配置,而是可以版本化、可迭代、可迁移的"软件资产"。
传统方法要么微调模型(成本高)、要么手动维护Prompt(效果不稳定)。SkillOpt的核心思想是:训练程序(Procedure),而不是权重(Weights)。
它把一个紧凑的自然语言技能文档(best_skill.md)作为优化目标:
整个过程像给Agent装了一个“执行策略大脑”,让它不断自我迭代、自我优化。

SkillOpt 网站截图
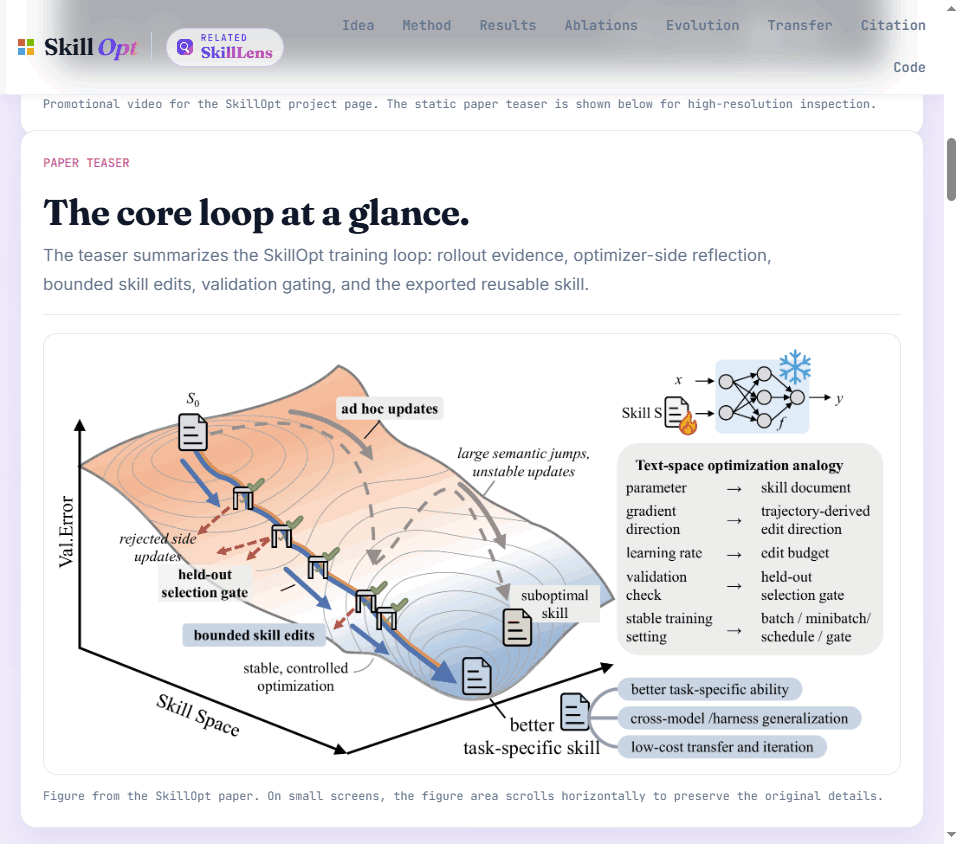
传统的神经网络训练,是通过“训练轮次(Epochs)”、“批次(Batches)”和“学习率(Learning Rate)”来不断调整模型内部的参数权重。
而 SkillOpt 认为,Agent 的核心技能其实就是那份包含指令、工具调用指南和少样本示例的 Markdown 文件(best_skill.md)。既然模型权重被冻结(Frozen)了,那我们就直接对这份“文本文件”进行梯度下降!
它的自动化训练闭环非常精妙:
运行实战(Rollout):让 Agent 在基准测试中实际跑一跑,收集它的工具调用、报错反馈和最终得分。
反思与编辑(Reflection & Edits):把成功和失败的案例分开。由一个“优化器模型”进行反思,对现有的技能文档进行结构化的“增加、删除、替换”微调。
文本学习率(Bounded Edits):设置“编辑预算”,防止优化器用力过猛,一下子把之前好用的规则给重写了。
验证门控(Validation Gate):只有新版本在验证集上的表现确实变好了,才允许更新!
绝对的零推理成本(Zero Cost) 以往很多提升 Agent 能力的方法,需要在运行时疯狂嵌套反思链、自我纠错,导致 Token 费用暴增、响应极慢。而 SkillOpt 所有的折腾都在训练期完成,最终部署的只是一份优化好的文本文档,在线推理成本为 0!
效果逆天,吊打人类专家 在官方测试中,SkillOpt 在 SearchQA、SpreadsheetBench、ALFWorld 等多个权威基准测试中全线霸榜。在部分任务上,其准确率相比“无技能状态”直接暴涨了近 25%,甚至轻松超越了人类专家手工编写的顶级 Prompt。
极强的“跨模型迁移”能力 这或许是最让人兴奋的一点。通过 SkillOpt 训练出来的 best_skill.md 具备极强的泛化性。你在 GPT-5.5 上训练出来的技能文件,直接拿给 Claude Code 或 Qwen 同样效果拔群,再也不用为每个模型重写一套指令了!
自带 Gradio WebUI,可视化训练 它非常贴心地内置了 WebUI。运行 python skillopt_webui/app.py,你就能在浏览器里实时看到技能的进化过程、被修改的补丁(Patches)以及得分曲线,看着大模型自己疯狂“卷”学历。
SkillOpt 完美支持 Azure OpenAI、OpenAI、Anthropic,甚至支持通过 vLLM 本地运行开源的 Qwen 模型。
# 1. 克隆并安装环境
git clone https://github.com/microsoft/SkillOpt.git
cd SkillOpt
pip install -e .
# 2. 配置环境(填写你的API Key)
cp .env.example .env
# 3. 启动一键训练(以SearchQA为例)
python scripts/train.py --config configs/searchqa/default.yaml
从“手工搓提示词”到“自动化训练技能”,SkillOpt 正在把 Agent 开发带入工业化时代。如果你也厌倦了玄学调优,不妨快去 GitHub 给微软点个 Star,让你的 AI 智能体自己学会如何自学成才吧!















